
Gut Checks and Gumdrops: Testing AI in a New Land
by Dan Garmat
My Dutch friends celebrated when I spoke my first word, “kaas.” I joked, it’s a good baby’s first word in the Netherlands.

There are hard parts in navigating a new culture, language, and cuisine. They feel like situations where the learning curve looks steeper than I’m sure I can handle. To help get me over some of these more challenging moments where I’m not an expert (yet), I’ve occasionally tested what AI assistants can do. Bottom line up front: this helps me in the most stressful situations. This preserves my resources so I can take more risks to connect with the native people and culture. I’ve been fortunate enough to have the tools and time to invest in this, and it’s been beneficial in terms of what matters to me.
I tested a few prompts to navigate uncertainty in a new environment, a “gut estimate” of their difficulty on a scale of 1 to 10, and how I grade ChatGPT 4o and Claude Sonnet 4 performance. Here is my first. Picture it. Netherlands, 2025:
The Epic Fail Test
Situation: At the grocery store and want to test the famous Dutch licorice, but can’t read the packages. I know some is sweet and tasty, some is salty and, ahem, an acquired taste. But I might not know which is which.
The idea: Can Claude extract text from a picture, determine the language and context, and provide a reasonable response for something that should be clear-cut?
The prompt (including an image and a question):


Analysis:
NOT GOOD ENOUGH!!! The words on the blue and green bags are different by one crucial letter:

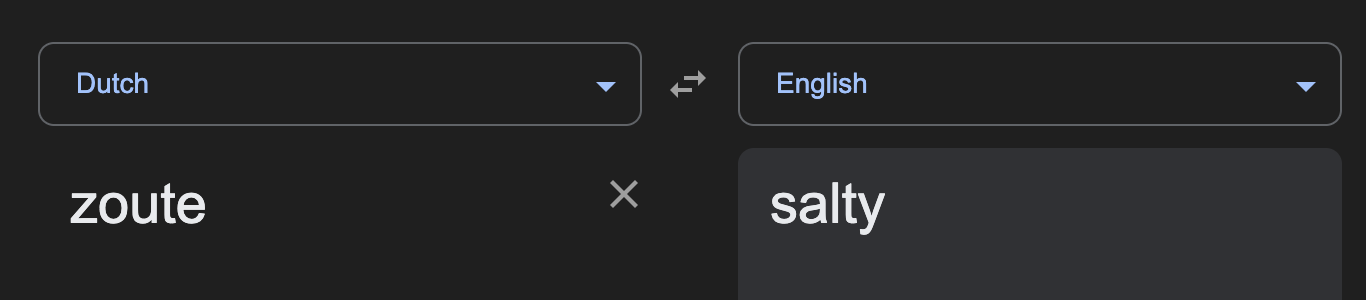
Eating licorice is already an arguably masochistic act. Salty licorice is a step further. I need to know when I can trust this model, so I tested whether it would reevaluate this:



It took three follow-ups. This is not good. The model has the raw capabilities needed to accomplish the task, but when it needed to put them all together, it failed.
Task difficulty: 5 (out of 10)
Grade: F
The impact:
I went against the initial suggestion that they’re the same and got the blue package of sweet licorice, which was the right choice. I liked the gumdrop-shaped one the most, as it was the softest.
The Lesson:
The AI assistant may be able to get the right answer on something this tough with this little context, but it may require the right prompt. If I’d given it more detail in that first prompt, it’d have provided more context on what’s important to me in the current task, reserving computation for solving that task, rather than figuring out what I’m even asking it to do. And it won’t necessarily double-check the first time I ask it to. It isn’t ready to be trusted with tasks that have a lot of “moving parts” or subtasks that require more guidance.
When it comes to translating uncertainty, cultural or linguistic, context matters. Prompts matter. And when it comes to licorice… trust, but verify.
Stay tuned for the next installment of Living in Beta, where I test whether AI can help me strategize luggage wrangling like a seasoned traveler instead of a chaotic human suitcase tornado.
For more on the importance of human oversight in AI interactions: The Human Element: Verifying Knowledge beyond the Prompt
For more on the collaborative dynamic between AI capabilities and human judgment: AI Executes, Humans Interpret